
Google Changes Rich Search Results for How-tos and FAQs
Last updated: August 2023
As the largest search engine and most important source of traffic, Google's policies are a very relevant part of the daily discussion for marketers and SEOs. With Google manager John Mueller's statement on "AI-generated content" and its impact on websites, the question of whether automatically generated content will be penalized by Google's webspam team comes up again and again.
The short version in advance: The added value for the user determines whether or not Google penalizes websites with auto-generated text. Even the current wave of AI generation tools has no influence on this principle. Therefore, from an SEO point of view, it is no problem to publish texts generated with AX Semantics. Even in very large quantities, as is the case with automated product descriptions, as long as they meet the known quality standards.
Check out our ticker for the latest on automated content, Google, and what's new:
August 2023: Google Changes Rich Search Results for How-tos and FAQs
It was unpleasant news for many SEOs: Google executes major changes to rich search results for how-tos and FAQs, as announced by the company itself. According to Google, these changes are intended to make search results more concise. Rich search results for FAQs will now only appear on trusted authority and health sites.
Instructions in rich search results will only be displayed on desktop devices, provided the mobile version of the site includes the appropriate markup. The changes affect the use of structured data on websites.
Search Console reports will reflect these changes, but will not affect the number of items covered. The changes will be rolled out globally from mid-August 2023, but website owners and SEOs should not panic. After all, FAQs have a positive impact on user experience and website usability. The rule of thumb is: Content should always be designed and created first and foremost for users.
June 2023: Google on New Policy about AI and E-E-A-T Content
There were several discussions at Google Search Central Live at Tokyo 2023, particularly around how Google is handling content generated by artificial intelligence (AI), as reported by Search Engine Journal. Here are the key takeaways:
- AI and Content Quality: Google doesn't distinguish between AI-generated content and human-generated content. The most important factor for Google is the quality of the content, regardless of its source.
- Labeling AI-Generated Content: Google itself does not label AI-generated content. However, the European Union is requesting social media companies to voluntarily label such content to counteract misinformation.
- Publisher Responsibility: While Google currently recommends publishers to label AI-generated images with IPTC image data metadata, they are not required to label AI-generated text content. Google is leaving it up to the publishers to decide whether it's better for the user experience to label such content.
- Reviewing AI Content: Google recommends having a human editor review AI-generated content before publishing. This applies to translated content as well.
- Natural Content Ranking: Google’s algorithms are based on human-generated content, and thus, they will prioritize and rank such "natural" content higher.
- AI Content and E-E-A-T (Expertise, Experience, Authoritativeness, and Trustworthiness): There are ongoing internal discussions within Google about how AI content fits within the E-E-A-T framework, given that AI cannot have personal experience or expertise in a topic. They will announce a policy once they arrive at a decision.
- Evolving AI Policies: Policies related to AI content are evolving due to the increasing availability of AI and concerns about its trustworthiness. Google advises publishers to maintain their focus on content quality during this transitional period.
March 2023: What is Bard? - A Short Introduction to Google’s Chatbot
- What is Bard and how does it work?
Bard is a conversational AI developed by Google and powered by a light version of LaMDA – Google’s large language model trained on texts and web data containing a total of 1.56 trillion words. Bard is able to generate text-based responses to prompts, summarize information from the internet, and supply links to relevant websites. It’s important to note that Bard is not a search engine, but rather a feature that aims to provide an interactive method for exploring topics and to help users investigate knowledge and explore a diverse range of opinions or perspectives.
- How was Bard trained?
In short, Bard was fed information from the web, which it converted to text. The responses were crowdsourced and evaluated using metrics such as meaningfulness, accuracy, and relevance to improve the chatbot's performance. However, it remains unclear what values and beliefs the crowdsourcing raters had, how they were selected, and what individual or subjective viewpoints, they might have had that might have influenced the evaluation of the given information.
- Why has Google created a chatbot?
Many see Bard as a response to OpenAI’s ChatGPT and think that the release of Bard was driven by the fear of falling behind in the technological race. However, Bard's launch suffered a setback in February 2023, when a demo showcasing the chatbot's capabilities contained a factual error, leading to a loss of confidence in Google's ability to navigate the AI era and a significant drop in market value for the company.
However, Google envisions the future of Bard as a feature in “search that distills complex information and multiple perspectives into easy-to-digest formats”, as Google wrote in their announcement of Bard. Also, Google has recently published research on making large language models cite their sources, which is likely to be crucial for information-seeking scenarios.
February 2023: "You can use AI to help you write better content"
You let a machine write your content or you got a fleet of copywriters? Well, Google does not care, as they confirmed in a statement on February 8. What is important is the helpfulness of the content - and that content is not produced in order to manipulate search results. Google writes:
"Google's ranking systems aim to reward original, high-quality content that demonstrates qualities of what we call E-E-A-T: expertise, experience, authoritativeness, and trustworthiness."
Google
The focus is solely on content quality rather than the way in which texts are produced. In this regard, Google specifically names AI-generated content and content automation:
"Automation has long been used to generate helpful content, such as sports scores, weather forecasts, and transcripts."
Google
AI, so Google, "has the ability to power new levels of expression and creativity, and to serve as a critical tool to help people create great content for the web."
February 2023: Google introducing Bard as an answer to ChatGPT
As some people and even SEO experts have declared that ChatGPT is going to be the death of the world’s largest search engine, Google released their answer to ChatGPT: Bard. The basis of Bard is LaMDA, which is Google's large-scale language model.
Sundar Pichai, CEO of Google and Alphabet, released a statement with the introduction of Bard. He describes it as "an experimental conversational AI service.”
As of now, Bard is only available to “trusted readers” but is supposed to be available to every user in just a few weeks. Google demonstrates how Bard will work in this depiction:
Like GPT-3 text generators as well as ChatGPT, Bard is relying on enormous amounts of text, available on the internet. This means that it draws information from the web to provide users with answers to their questions.
It remains to be seen how Bard will change Google, but also if it will drastically reduce informational search traffic for websites, like some predict.
January 2023: Google Reiterates Guidelines for AI Written Content
With the release of and hype about ChatGPT, Google has reiterated it’s guideline. But it was the financial services company Bankrate that provoked Google to reiterate their guidelines, as seoroundtable.com reports. Why? Bankrate had been using AI for their content production. And they have been very successful with it in search engines like Google. It’s been going so well that even Sistrix analyzed the high rankings of Bankrate’s AI content.
And Google felt compelled to make a statement about their automated content guideline:
Furthermore, Google clarified that automated content is not an issue per se:
“As said before when asked about AI, content created primarily for search engine rankings, however it is done, is against our guidance. If content is helpful & created for people first, that's not an issue.”
Google
How does Google evaluate automated content?
There was some excitement as Google Executive John Müller was asked about Google's view on AI-generated content during a Hangout at the beginning ofApril 2022. He stated:
"We consider AI-generated content to be a breach of webmaster guidelines."
Google Executive John Müller
This was often understood as a general rejection of automated content. But the Google Webmaster Guidelines clearly show: Google's attitude towards automated content remains unchanged.
Google Webmaster Guidelines: Punishment for manipulative intent
The Webmaster Guidelines still state that automated content is a problem if it has a manipulative intent and is not created to add value for users.
"If search rankings are meant to be manipulated, and content is not meant to help users, Google can take actions regarding that content."
The actions meant here are manual and require a human review, not automated ranking penalties.
Poor content and spam are the problem, not automation itself
At this point, therefore, Google has no intention of using technical methods for recognizing automated content. Instead, the search engine uses the content and formal spam criteria for this type of content, as it does for handwritten texts.
It would be technically possible to identify some content generated by large language models, but not content generated by data-to-text solutions such as AX Semantics. Only the traditional spam indicators, such as poor linguistic quality or content-free speech junk, could be detected in this case. For content generated with an emphasis on user value, such as product descriptions or automated news and weather texts, Google does not penalize the content. Also, Google tolerates the simultaneous publication of high volumes of content, so long as it is not spam.
| Which automated content is considered suspicious by Google? Source: Google Webmaster Guidelines Automated Texts - Pointless text, in which keywords are distributed. - Automated translated text without validation or underlying set of rules. - Very simple automated text based on Markov chains or using synonymization or concealment techniques. - Content compiled from different web pages without sufficient added value. |
The reason for the current discussion: AI hype due to ChatGPT and GPT-3 tools that do not have a rule-based approach
The current discussion is due to the widespread use of ChatGPT and GPT3 tools. Once again, it is important to point out the difference between GPT and the data-to-text approach of AX Semantics.
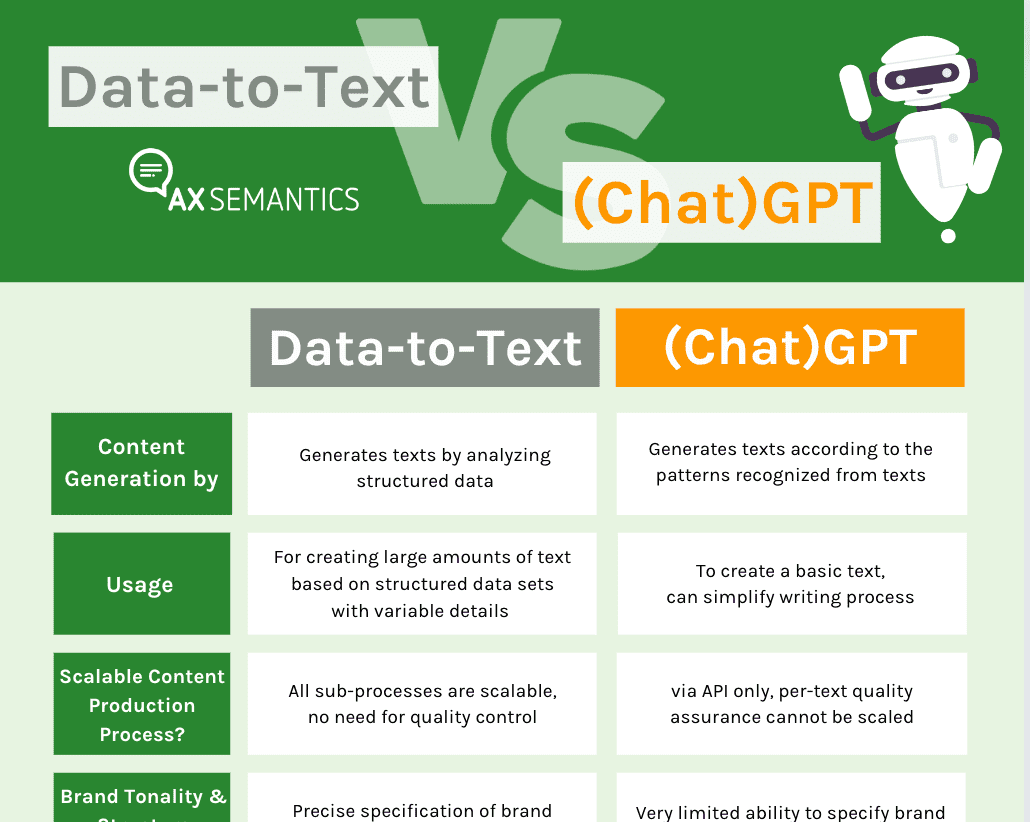
SEO, Data-to-Text, and GPT
SEO Expert Miranda Miller from Search Engine Journal, points out quite rightly that there are a lot of established AI content projects that have great content (and rank well on Google with it):
"The Associated Press started using AI to generate news in 2014. Using AI in content creation is nothing new, and the most important factor here is using it smartly."
SEO Expert Miranda Miller from Search Engine Journal
But which software is more reliable as regards SEO: data-to-text or GPT?
- The content created with data-to-text is based on data and data interpretations, rather than meaningless generalizations. The content meaning - and therefore the user value for Google - is determined by users (via logics, stories and triggers). So there are semantics in the texts, not just correct syntax.
- In data-to-text software, users review every decision made by AI components in the system. So they are involved in all decisive phases of the content generation.
- Some software can determine whether a text is based on large language models, but there is no technical way to identify data-to-text content.
Get started!
Our experts will answer any questions you may have about our software, your potential use case, etc.

FAQ
What is content automation?
Automated content generation with AX Semantics works with the help from Natural Language Generation (NLG) - a technology that generates high-quality and unique content on the basis of structured data that can't be distinguished from manually written content. Typical uses for text automation are product descriptions, category content, financial or sport reports or content for search engines websites - in a nutshell, all kinds of content that require large quantities and have a similar fundamental structure.
Structured data is data that adheres to a pre-defined data model and is therefore easy to analyze. Structured data conforms to a well designed pattern, for example a table showing connections between the different rows and columns. Common examples of structured data are Excel files or SQL databases. Structured data is an important basis for automated content generation. For product descriptions in e-commerce, for example, these are often available in a shop system, product information system (PIM) or in the shop.
Numerous AX Semantics customers results show that automated content is worthwhile when it comes to SEO. The e-commerce company MYTHERESA increased its visibility by 80% for relevant keywords within 6 months after beginning to use automated content. KitchenAdvisor is another example. They also registered a 0.7 to 1 increase in Sistrix visibility within 3 months.
AX Semantics software is configured to produce thousands of unique pieces of content. Most users subsequently publish the content on the web, with the aim of gaining visibility on Google, among other things. Therefore, there are various functions in the tool (sentence variants, synonyms, triggers, sentence sequences, etc.) to ensure variance and uniqueness. Fundamentally, this is how it works: After an initial configuration, you can use the software to generate unique and high-quality content based on structured data. You create one-time logics, content blocks and as needed variances for all possible "events". This way, evaluations, assessments and conclusions can be made in the text. Based on this and the information it finds in the data, the software forms content based on natural language. Then, each time content is regenerated, the software assembles the components into a new unique content, following the predefined rules.


